I don’t understand how to correctly add data for indexing.
I have data in a supabase table and I receive data through the postgresql connector.
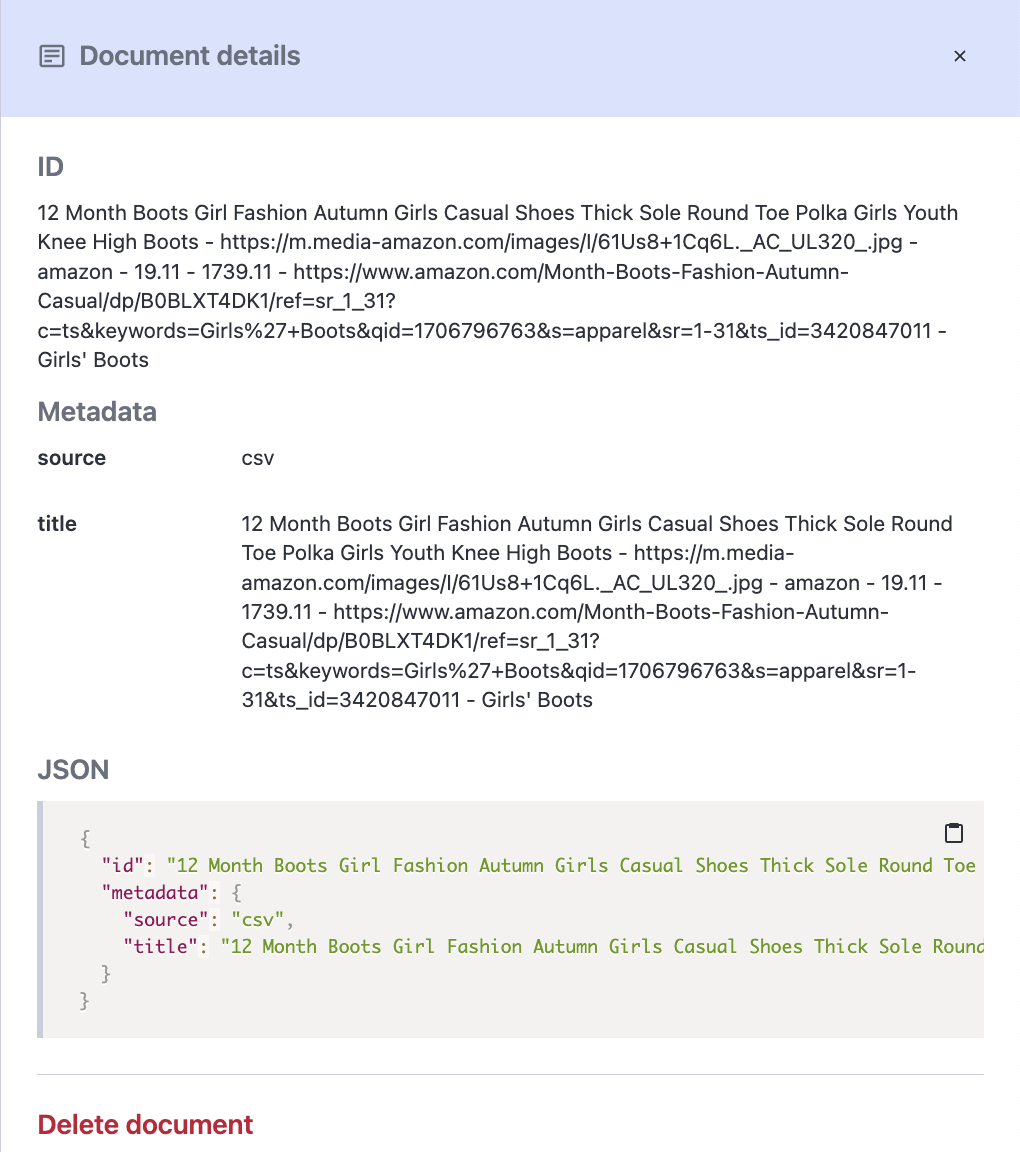
Supabase:
public.ecommerce (
id uuid not null default gen_random_uuid (),
created_at timestamp with time zone not null default now(),
product text null default ''::text,
image_url text null default ''::text,
usd real null,
rub real null,
link text null default ''::text,
category text null default ''::text,
market text null,
constraint ecommerce_pkey primary key (id)
) tablespace pg_default;
vectara-ingest:
vectara:
corpus_id: 6
customer_id: 2252938633
reindex: true
crawling:
crawler_type: database
database_crawler:
db_url: 'postgresql+psycopg2://postgres.**************:*************@aws-0-eu-central-1.pooler.supabase.com:5432/postgres'
db_table: ecommerce
doc_id_columns: [product, image_url, market, usd, rub, link, category]
text_columns: [product, image_url, market, usd, rub, link, category]
The data was added, but I think that somehow I did it incorrectly, since the information is duplicated.
There are a lot of fields in the documentation, but it’s not clear exactly where to add what.
Tell me how to properly organize the data of products from the marketplace?
Let me try to explain. The idea here is to have a way to generate a Vectara document from each row in the table. The customization is as follows:
- title_column is a text field in the source table that will be used to populate the “title” of this document.
- text_columns is a list of column names (1 or more) that are concatenated together to generate the main text field of the document. Those need to be primarily text fields, for for example in your case above I see “usd”, “link” and “image_url” which are typically not a good choice for this. Alternatively in a product search application I would include the product name, a description, reviews, etc. Anything that is a good text field.
- you can also use “metadata_columns” to populate other fields that are not textual in the Vectara metdata.
- “doc_id_columns” is a special field use to aggregate rows into a Vectara document. If it is unspecified, then vectara-ingest will aggregate every 500 rows and make a random documentID for each Vectara document. If you do specify, then each documentID becomes a concatenation of all the fields specified. In your case, I would pick something that is a good unique ID of a product - is that “product”?
db_table: ecommerce
doc_id_columns: [product]
text_columns: [product, category, market, usd, rub, link, image_url]
Why is there no information from this column?
text_columns: [product, category, market, usd, rub, link, image_url]
db_table: ecommerce
doc_id_columns: [product]
text_columns: [product]
metadata_columns: [category, market, usd, rub, link, image_url]
For some reason there are no other columns except title.
Can you please share the source CSV file (or perhaps the first 10-20 rows in it)?
This worked for me:
doc_id_columns: [product]
text_columns: [product]
metadata_columns: [category, usd, rub, image_url]
I did not see “market” or “link” as columns in the document.
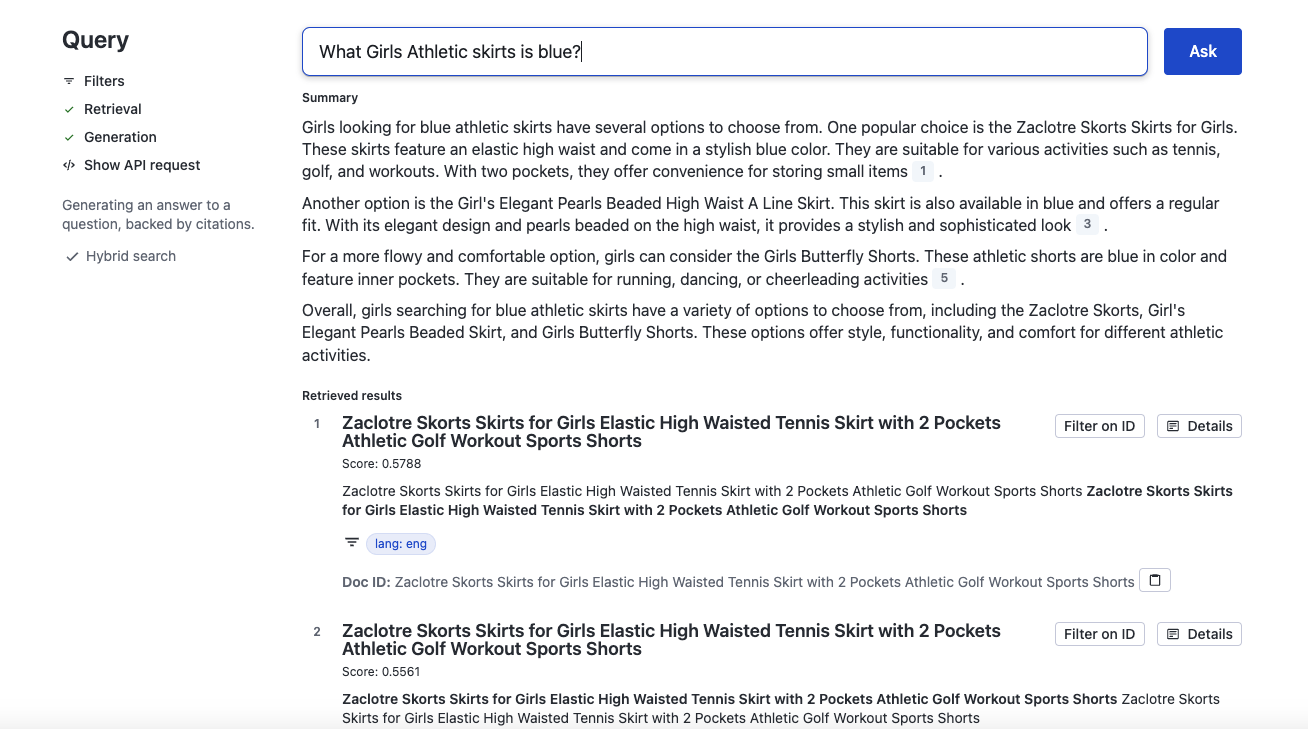
Can you show how the information was added to Vectara?
Here’s an example of how it looks when issuing a query.
Why I don’t see all fields?
db_table: ecommerce
doc_id_columns: [product]
text_columns: [product]
metadata_columns: [category, author, usd, rub, url, image_url]
Why can’t I see all the fields in the card, but only the title field?
Where is the category, author, usd, rub, url, image_url data?
Hi,
With Vectara there can be two types of metadata. (1) The doc_metadata and (2) “section” metadata.
- Document level metadata is what you see in the console and attached to a whole Vectara document
- A Vectara document can be split into multiple “sections” and section level metadata is attached to each section.
(see for example https://docs.vectara.com/docs/api-reference/indexing-apis/indexing#index-request-and-response)
In the csv crawler, the code currently adds “title” and “source” as the document level metadata. Each row is considered a “Section” and the metadata from each row is added to the section level metadata.
Does that make sense?
If you run a full query using the API you will see the variou sections returned and the right metadata associated with each section.
1 Like
I don’t really understand how I can add fields correctly so that they are correctly indexed and displayed?
I need to add this table